What is a viral video ?
Our ultimate goal being to find outlier videos that made more views than others, we first have to define what makes a video viral. This question definitely has many possible answers as many factors come into play. Here are a few of them:
- The video has more than a certain number of views (ex. one million)
- The video has more views than the channel’s past month’s average.
- The video has a better like/views ratio than other ones.
- The video has a better views/subscribers ratio than other ones.
We went with the fourth definition in our work because it would pick videos mostly seen by non-subscribers. This would be explained by the fact that they were either recommended by the YouTube’s algorithm or were manually searched for, which we thought was a good description of viral videos. Here are more mathematical details on the way virality was defined.
Let’s first define some logic requirements :
- The more views it gets, the more the video is viral.
- Doing as many views as smaller channel is not considered equal success. Virality must decrease with subscribers.
- Big channels should also have a chance to have a video go viral.
From the distributions of the number of views and number of subscribers we want to use log(views+1) and log(subs+1) transformations, so our first attempt will be the ratio

.
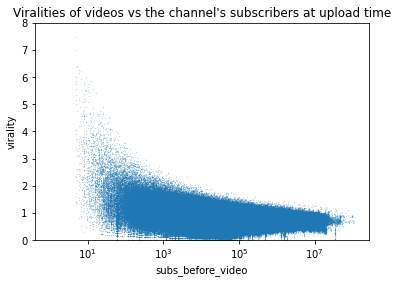
It’s better but it’s clearly harder to be viral at high number of subscribers. Highest viralities seems to decrease in -log. Hence we compose with the decreasing exponential ‘exp(- . )’ to make them linear.
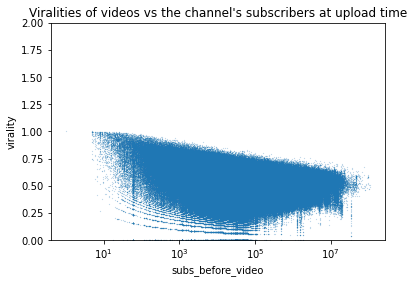
It’s a success ! Now 1 – exp(-.) keeps the monotony (high virality = high value). Note that the values are generally between 0 and 1 since exp(-.) > 0 and the ratio is generally positive so exp(-.)<1.
There is still bias, but this time it is linear so we just need to add a line to compensate. Graphical interpolation to find ax+b yields a=0.055 and b=0.05.
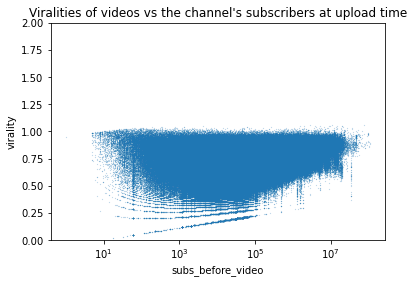
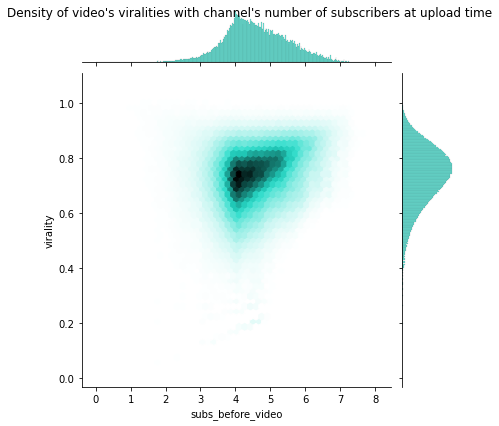
We see that the data is still concentrated around high values (see heatmap) : let’s spread them around by taking it by the power 2.1 (another empirical value). Since they are between 0 and 1, their mean will decrease.
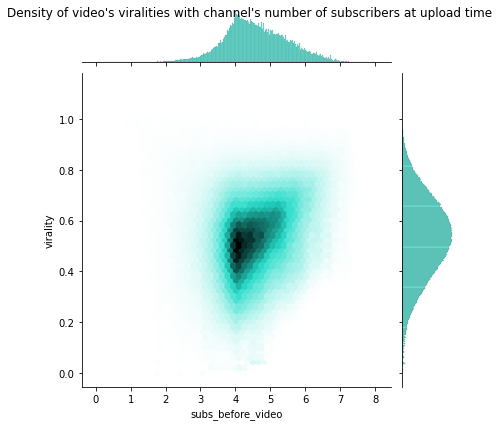
We will hence use this formula in our analysis to define the success of a video.
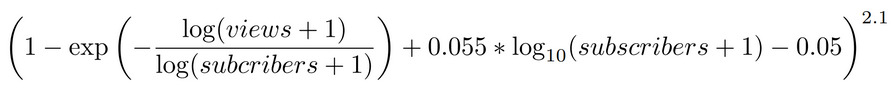
How does the data look like ? What makes a video viral ?
Each video is defined by a specific features. These include the title, the duration, the tags, the description and the number of subscribers at the release of the video. Note that those are the ones known before the release of the video. We also know its number of views, likes and comments but these are features that will come aftere the release of the video. We want to compare videos with features known before its release to maximize our chances to make it viral.
In the following section, we will take a look at each feature and see if there is any statistical difference between viral videos and non-viral.
Titles
We first had a look at the titles, as it is one of the first elements that we notice when seeing a video on Youtube. Let us first compare their lengths.
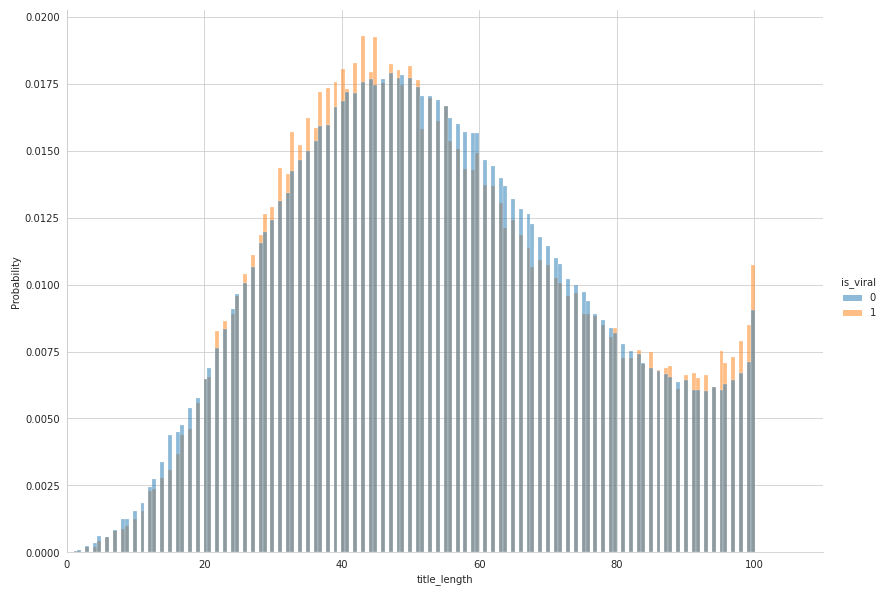
A first remark is that title lengths cannot be longer than 100 characters, as we can see on the plot above. We see a trend for viral videos to be a bit shorter than non-viral ones. The difference between the two means are not statistically significant though.
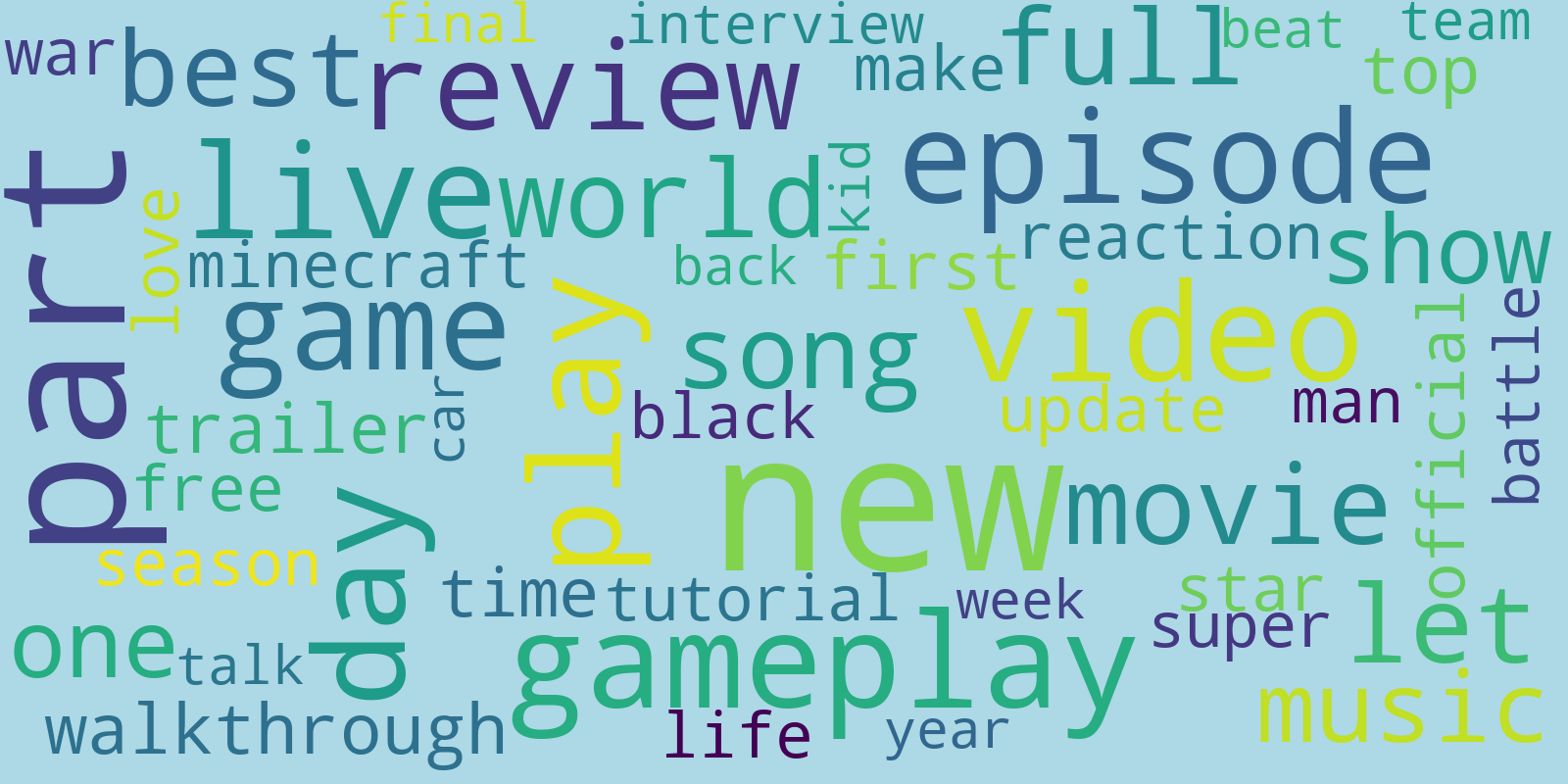
After some data cleaning (ponctuation, links, tokenisation, stopwords...), we can then form word clouds for both of them. For the non viral sample, we got the following one:
and for the viral sample, we got:

Hum they look very similar… This is because some words like ‘video’,’part’, ‘new’ or ‘episode’ are very often used in youtube title and are not very specific. To circumvent this issue, we have repeated the same process but without the intersection of the top 200 words from the viral sample and the non viral sample. This way we get for the non viral sample:
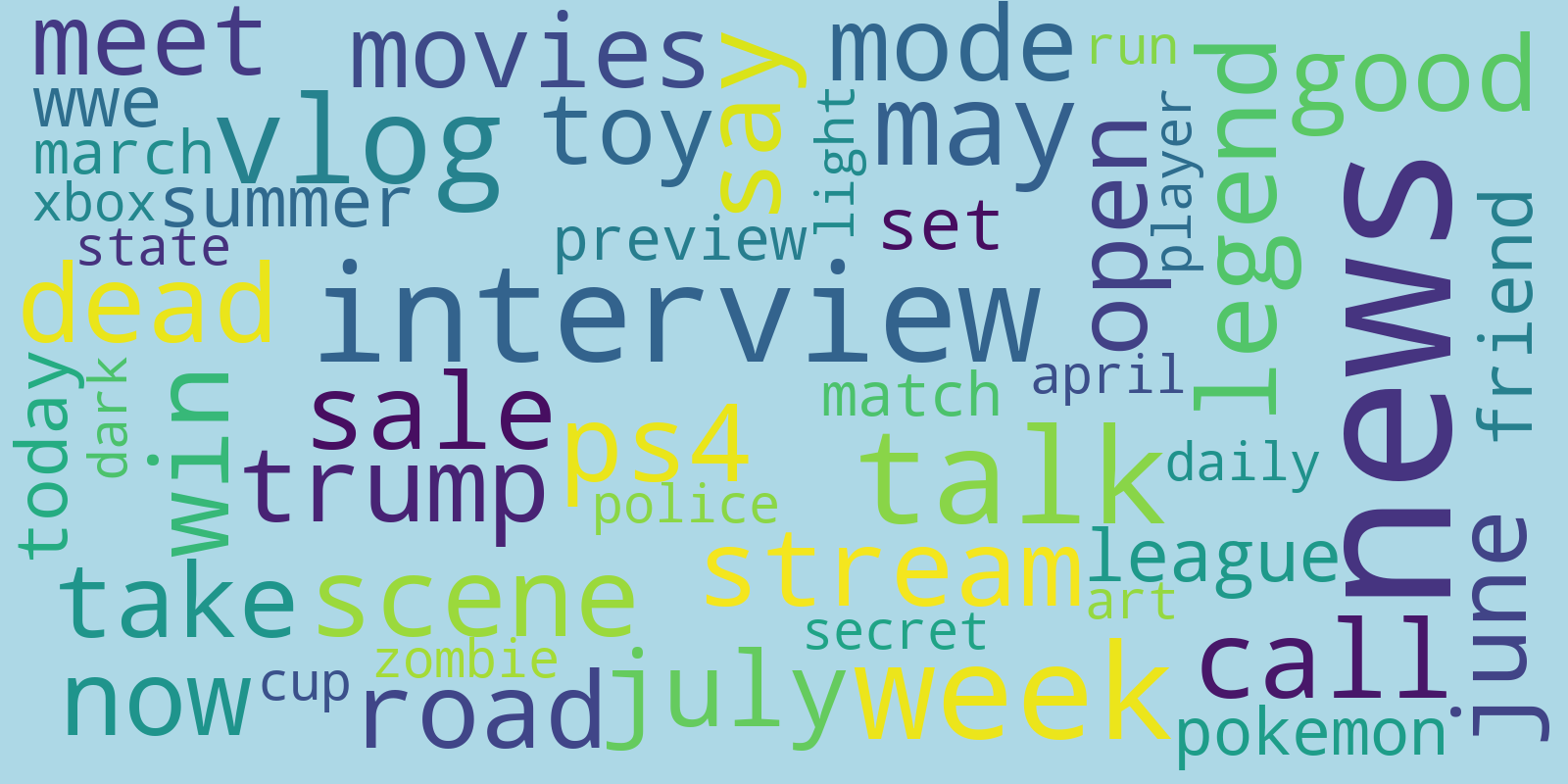
and for the viral sample:
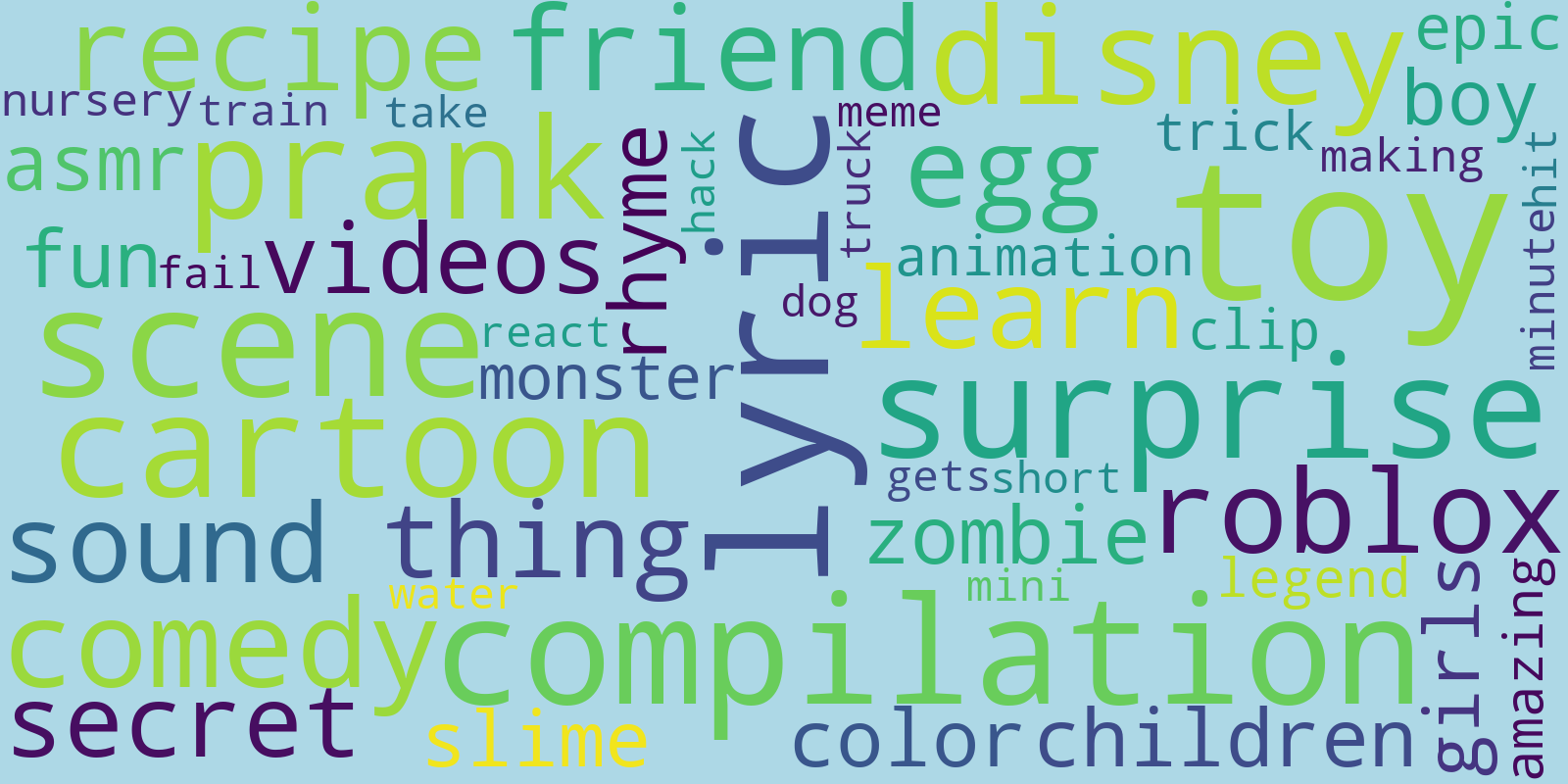
Fron this, we can see that frequent words specific to the viral sample include trendy topics such as ‘prank’, ‘asmr’, ‘slime’ or ‘roblox’. It is not surprising to see words as ‘lyrics’, ‘hit’ or ‘rhymes’ which are related to music videos subject to be watched many times by the same viewers.
Duration
Another factor that comes in mind is the length of videos. A common thought is that viral videos are short. What does the data tell us ?
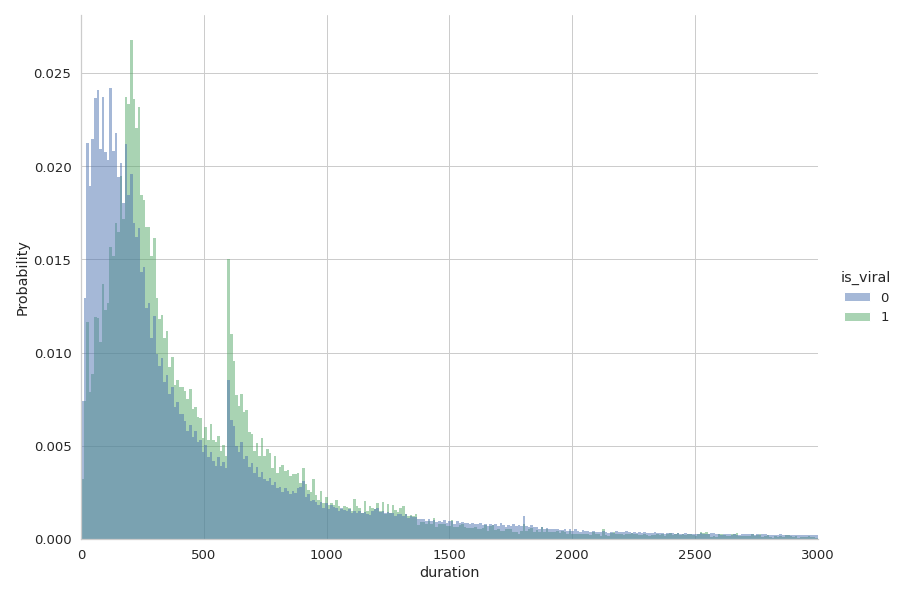
Again, we can see a clear precise mark at about 600 seconds = 10 minutes. Passing the 10-minutes mark on YouTube videos is very important: they let creators put more ads on their videos. Creators thus often release videos of just about 10 minutes. It seems from the plot that viral videos are longer than non-viral ones but the following error bars tell otherwise.
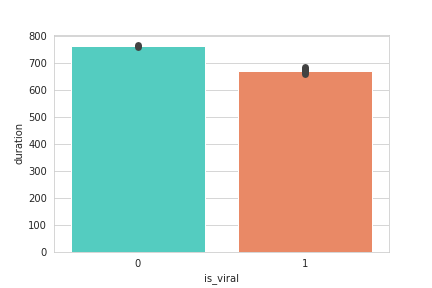
Non-viral videos are in reality shorter because there are some exceptionally long outliers which increase the average durations of videos.
What about hashtags ? Does putting a lot of them help having more views ?
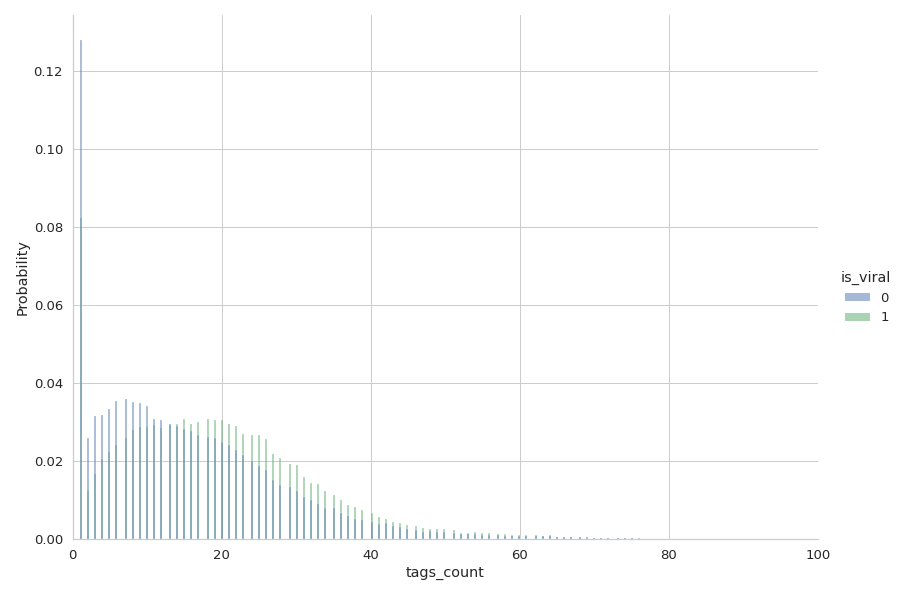
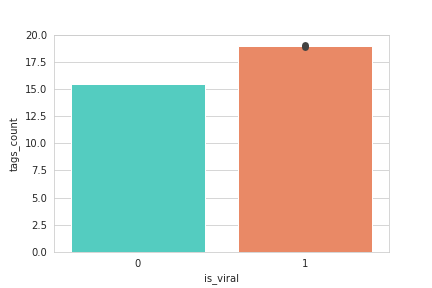
Definitely ! It is widely known that your videos can be seen by people that simply search for certain subjects. The data agrees ! Again, it is proven by the following error bars.
Description length
Is it useful to write huge descriptions to gain more views ?
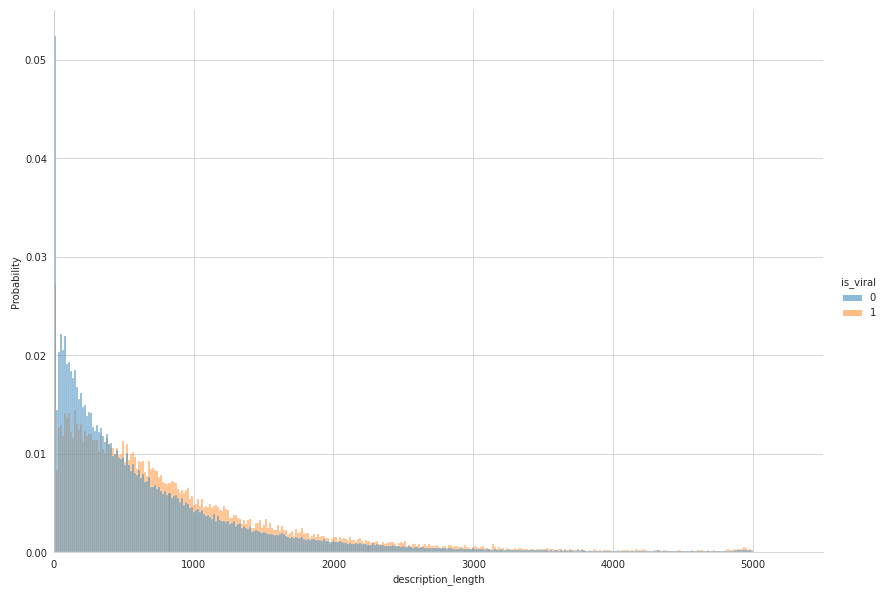
It is apparently the case ! We see a hardstop at 5000 characters which is the maximum length of descriptions on YouTube. We definitely see that viral videos have longer descriptions, proven again with this test:
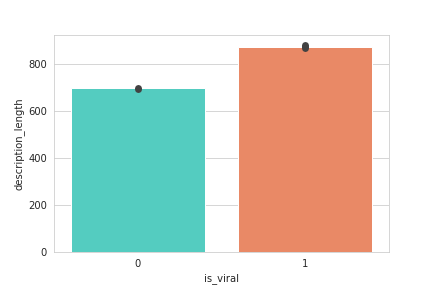
We recommend providing a precise description of your video if you want to increase views !
Number of subscribers
Finally, does already having a lot of subscribers help make your video go viral ?
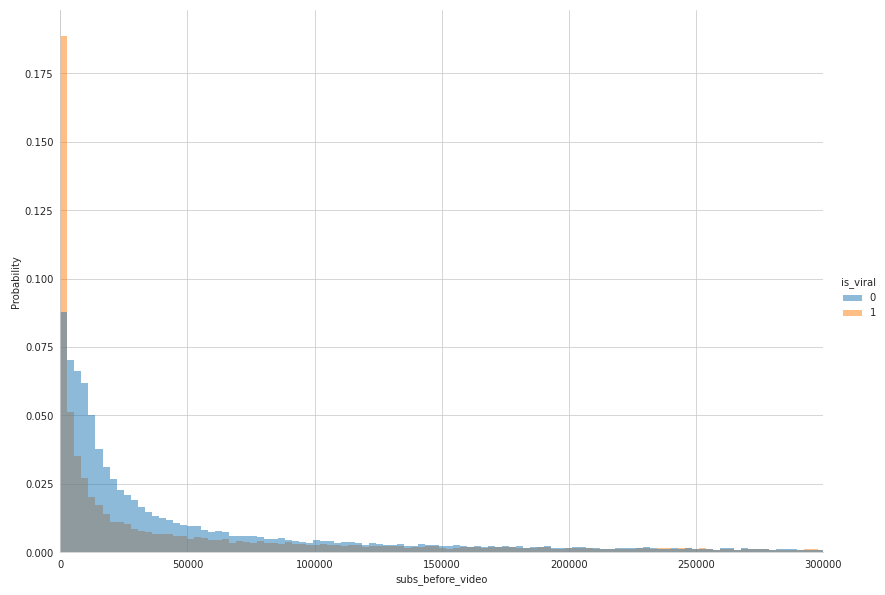
From this distribution we may have the impression that non-viral videos have more subscribers. But change your mind looking at the following error bars:
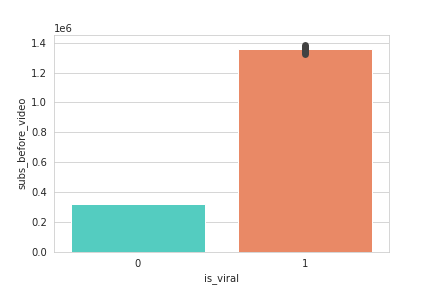
We can definitely see that the subscribers' mean is way higher in viral videos. In fact, this is explained by outliers which are not shown on the plot.
A few correlations between features
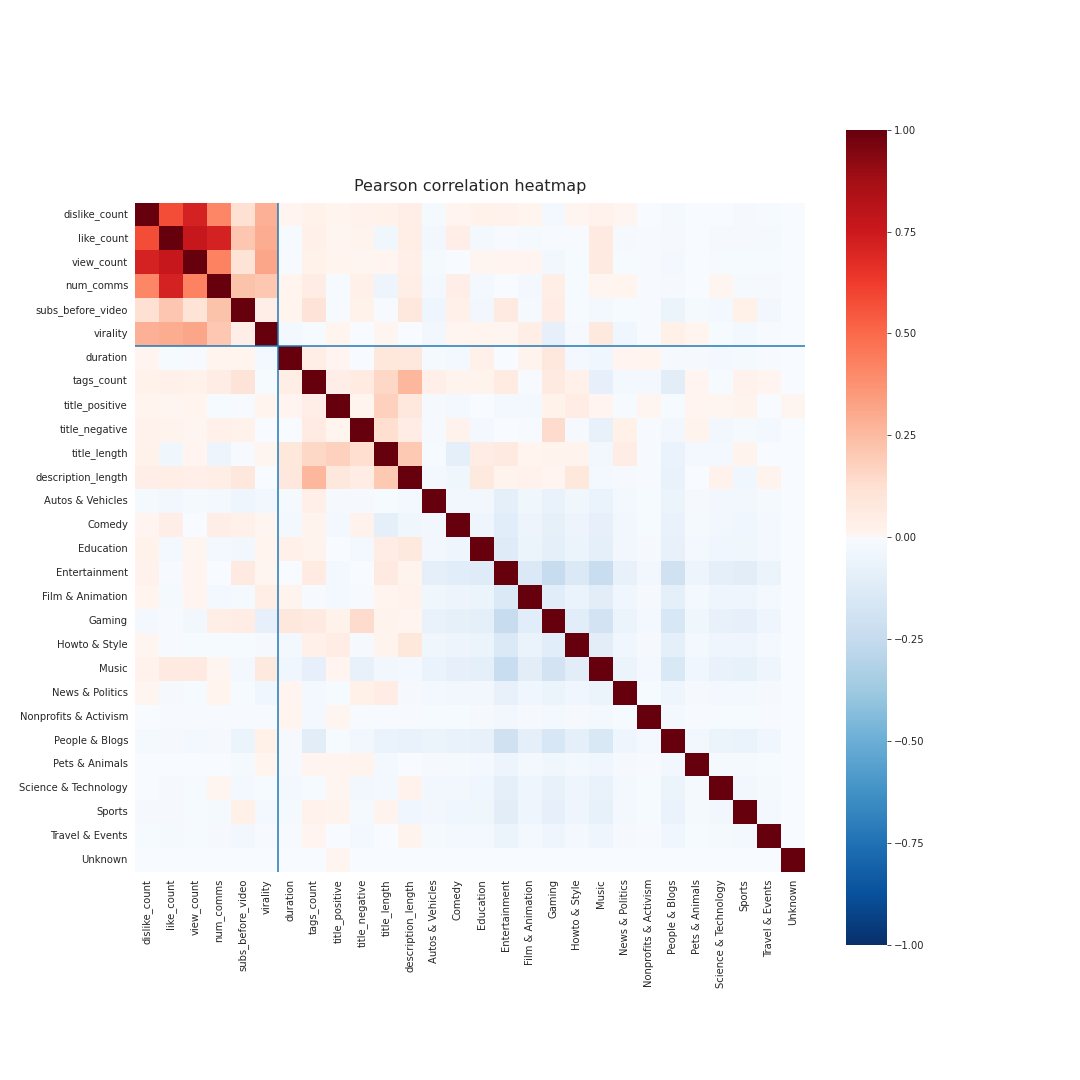
Here a correlation heat map which shows that the features that we talked about above are not correlated with each other. We can thus use all of them for our classification model.
Predicting virality of new videos
How did we tackle this question ?
This is the question we are all waiting for. Long story short: we do not really know... at least with the features in our dataset. What we tried to do is train some machine learning models on features we thought any content creator could control, and see which ones really made an impact.
Like we saw previously, we do not have access to major aspects of the videos, such as its thumbnail, the political context at the time of its upload date, and most importantly its actual content. It is of course very hard to say if a video will get viral if we do not know the content of it ! Viral videos often need to connect people, to be emotionally strong or funny ; but we do not have access to these details. Thus, we can only tell if a video will get viral based on:
- Its category (Music, Gaming, Politics, Sports,...)
- Its channel's number of subscribers
- Its duration
- Its title's and description's lengths
- Its number of tags
- How many positive and negative words the title contains
These features were the ones we selected to build our model. We tried a few different models including logistic regression, random forests and XGBoost.
We first split the total dataset into train and test sets, and then trained the models on the train set using some cross-validation to find the best hyper-parameters (like the number of trees for example).
The results and best model
The results we got are summarized in the following table :
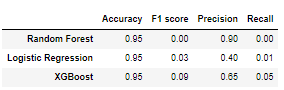
Having a precision of 65% means that you have a 65% chance of your video getting viral if our model says it does.
Having a recall of 5% means that our model will recognize 5% of viral videos as such.
When our model predicts a video as viral, we want our video to actually go viral with the highest probability. Therefore, we prefer having a more conservative model that will prioritize precision over recall. XGBoost has a pretty good precision, which is why we chose it.
Its results can be summarized in the following confusion matrix:
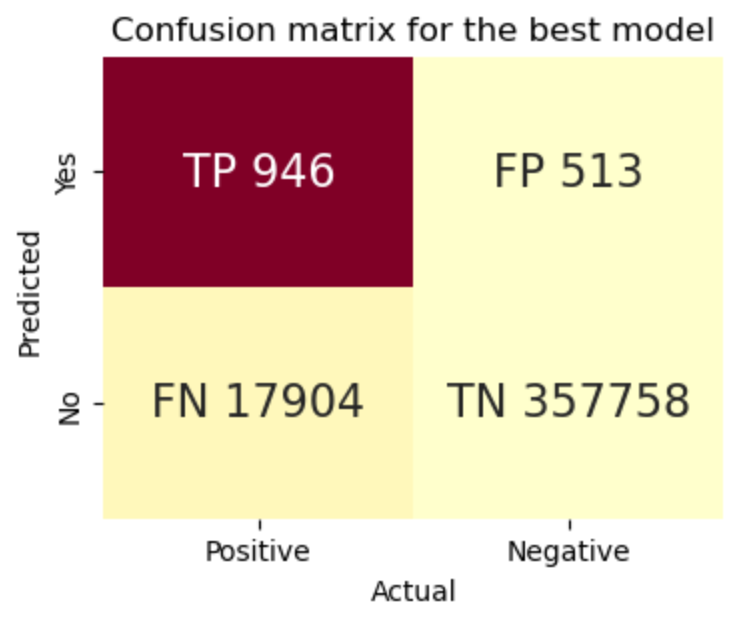
However, this choice should raise four questions :
- “But wait, don’t we have an accuracy of more than 95% ? Isn’t that a super performance ?”
Well yes... normally ! This metric measures how many correct samples we recognized in total. Although it may seem high, accuracy is actually not a really good metric when classes are skewed, which is our case. Since we have about 95% of negative elements and 5% of positive ones, it performs hardly better than a dumb classifier only outputting "false".
- “Random forests have a precision of 90%… Why not choose that one?”
Well, if it would have a precision of 90% and have values of the other metrics comparable to those of XGBoost, we would've obviously chosen that model. However, the reason it wasn't chosen is because it has a F1 score and recall of ... close to 0%. What this concretely means is that the model will only recognize "viral" videos about 0% of the time, which isn't ideal at all.
- “Okay, so what can you concretely do with your chosen model?”
Well, we could look at the importance of the coefficients and see which ones are most important. We could also try and look at different combination of features and see if the model predicts the video to go viral. For example, we can look at whether a channel with 10'000 subscribers, outputting a two minute gaming video with a 40 character long title with 3 insulting words and a whole bunch of tags in its 400 character description could have a chance to go viral. However, as we clearly miss some very important features, we unfortunately get very poor results when trying to predict a video's virality.
- “So, if we find some kind of way to encode video content, the socio-political context and the thumbnail, we should get a great model ??”
Well, another hypothesis we have is that... there is sadly no real magic formula to make a good video. There's probably a good reason that no one managed to find a way consistently upload viral videos, which is that there isn't any !
What should you do to become a famous YouTuber ?
Through this entire dataset analysis, we learnt that there is no magic way to make a video go viral. Videos' virality depends on too many factors that we do not have in our datasets. Being able to make a viral video without content, just with a precise duration, category and title would disprove the Youtube's algorithm's efficiency. Even with many different machine learning models, the task was simply not possible to solve precisely.
Nevertheless, we still found some statistical significances between certain features of videos. In other words, there are definitely ways to *help* you make more views by tweaking certain parameters of your video. You could then try to feed it to our model to see if it has a chance of becoming viral. If it tells you it won't become viral, you can almost be sure to flp. If it tells you otherwise, you will still have a 65% chance of becoming famous !
Catch your camera, start recording and make some money !
This data story was brought to you by Corentin Tissier, Wissam Pheng, Sander Miesen and Pierugo Pace.